Hire Data & AI Developers In India
Onboard elite Data & AI developers in India to build high-intelligence and cloud-scale apps.
- Senior AI engineers in India building custom LLMs, RAG pipelines, and neural architectures.
- Agile teams ensuring rapid model deployment and scalable MLOps infrastructure.
- Direct access to technical leads for transparent, real-time global AI synchronization.
- Production-grade code from India optimized for inference speed and global scale.
Trusted by Global Enterprises, Leading Brands, and Growing Startups









Hire Data & AI Developers for Intelligent Products
Accelerate your cognitive roadmap with Webshark’s senior AI engineers, specialized in building high-performance neural networks and RAG pipelines. Our team leverages modern architectures like Transformers and LLMs to deliver intelligent interfaces that ensure sub-second inference and global scale. By prioritizing modular codebases and automated MLOps guidelines, we help global leaders reduce technical debt and maintain resilient, future-ready intelligence ecosystems at scale.
LLM & RAG Orchestration
Developing sophisticated context-aware AI pipelines using LangChain and vector databases to deliver enterprise-grade generative intelligence solutions.
Custom Neural Architectures
Engineering optimized CNN, RNN, and Transformer models in PyTorch and TensorFlow for high-precision computer vision and linguistic tasks.
Big Data ETL Engineering
Architecting scalable distributed data pipelines using Spark and Hadoop to transform massive unstructured datasets into analysis-ready golden assets.
Secure AI Infrastructure
Implementing robust data privacy layers and VPC model deployments to protect sensitive PII while maintaining strict international compliance standards.
Automated MLOps Pipelines
Streamlining model versioning and continuous training with Docker and Kubernetes to ensure resilient, horizontally scalable cloud-native AI deployments.
Predictive Decision Logic
Leveraging statistical learning and deep neural networks to forecast market trends and optimize enterprise-level business intelligence workflows.
AI Excellence Across Neural and Data Infrastructure Ecosystems
Hire dedicated AI developers with proven mastery in engineering high-intelligence applications with custom neural architectures and secure, cloud-scale data pipelines.
Generative AI & RAG
Architecting enterprise-grade RAG pipelines and custom GPT solutions using LangChain and LlamaIndex for context-aware, secure automation.
Neural Network Design
Engineering custom CNN, RNN, and Transformer architectures optimized for high-performance deep learning and real-time pattern recognition.
Cognitive NLP Logic
Building advanced Natural Language Processing modules for multi-lingual sentiment analysis, entity extraction, and automated text summarization.
Big Data Engineering
Building high-performance ETL pipelines and distributed processing logic using Spark and Hadoop to manage massive unstructured datasets.
Computer Vision Systems
Implementing real-time object detection, depth estimation, and semantic segmentation for surveillance, medical imaging, and retail AI solutions.

Scalable MLOps Fit
Containerizing AI models using Docker and Kubernetes to ensure low-latency inference and horizontal scalability across global cloud infrastructures.
Featured Work
A curated portfolio of high-intelligence applications engineered for neural accuracy, automated data orchestration, and global cloud-scale inference.
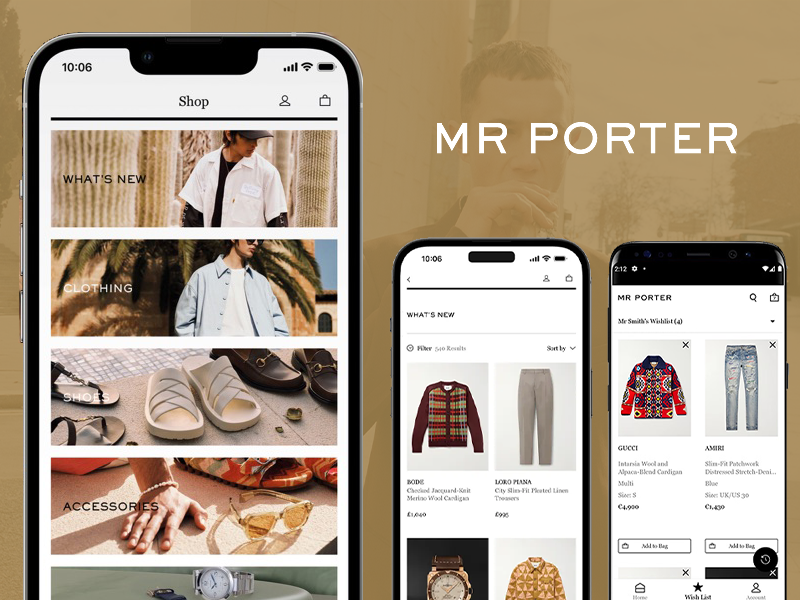
A conceptual redesign enhancing usability, visual clarity, and performance while maintaining the brand’s premium identity.

A conceptual redesign enhancing the digital experience for Stephen Webster’s iconic jewelry collections.

A scalable app redesign focused on faster ordering, improved usability, and a seamless food discovery experience for high-volume, on-demand users.

A high-performance digital redesign blending French elegance with a seamless, personalized e-commerce journey for Gemmyo’s bespoke collections.
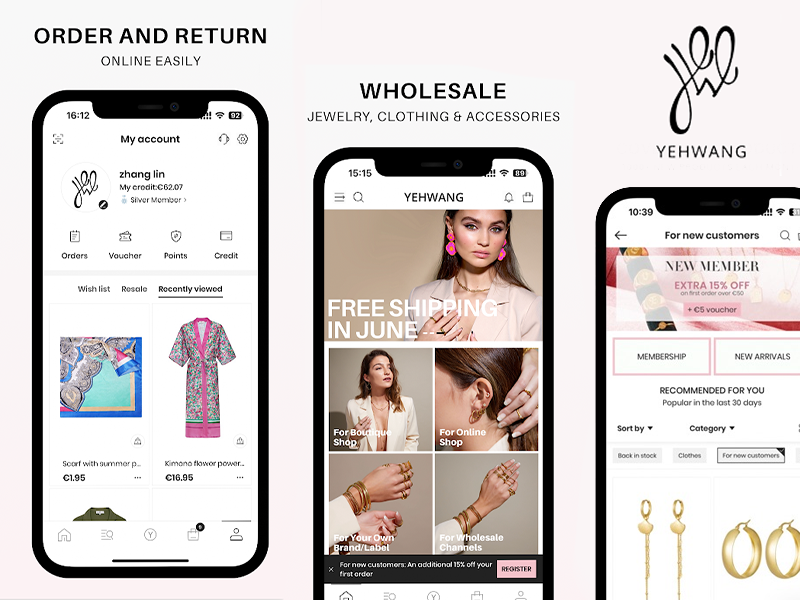
A refined mobile experience designed to showcase products, enhance browsing flow, and elevate brand presence for a fashion-forward global audience.

A sophisticated digital transformation showcasing Haddonstone’s craftsmanship through high-fidelity project visualization and refined product discovery.
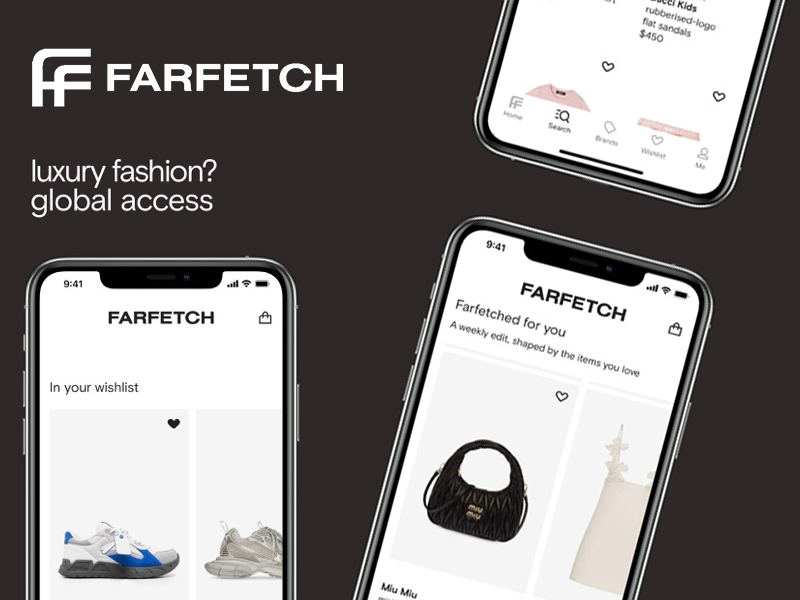
A conceptual redesign focused on premium storytelling, personalized discovery, and seamless navigation across a global luxury fashion marketplace.

A vibrant digital overhaul capturing Free People’s eclectic aesthetic with enhanced visual storytelling and a seamless, community-driven shopping journey.
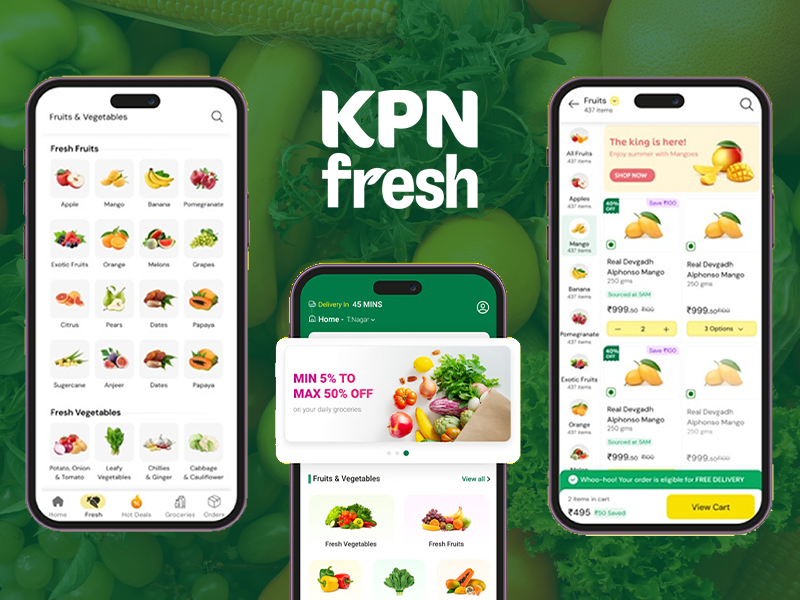
A fast and intuitive grocery delivery app experience focused on easy product discovery, quick reordering, and a seamless checkout journey for everyday shopping.

A sophisticated digital evolution for a Dubai-based construction leader, showcasing five decades of general contracting excellence and landmark regional projects.
Vetting Framework to Hire Data & AI Developers
A rigorous, data-driven process to onboard elite machine learning engineers and neural architects into your product ecosystem.
Define Scope
Outline your core model requirements, RAG architecture needs, and inference targets for precision talent matching across your intelligent enterprise infrastructure.
Curated Expert Sourcing
We shortlist elite engineers whose mastery in neural networks or transformer logic aligns perfectly with your specific AI technology production stack.
Algorithmic Logic
Evaluate technical mastery in hyperparameter tuning, weight optimization, and high-speed inference performance across various production AI scale benchmarks.
Rapid Integration
Onboard specialists into your automated MLOps pipeline with immediate, high-quality contribution to your active AI development production milestones.
Expertise in the Modern
Data & AI Engineering Ecosystem
AI Development Benchmarks to Mitigate Risk
Proven delivery of production-grade AI solutions designed for low-latency inference, high-throughput automation, and scalable neural orchestration.
Years of specialized engineering in neural networks, generative AI, and autonomous agent frameworks from our premium India hub.
Average low-latency inference standards achieved for real-time model predictions and high-velocity data pipelines globally.
Rapid deployment of vetted AI specialists ready to integrate into your MLOps pipelines and active development sprints immediately.