Hire Dedicated NLP Specialists In India
Enterprise LLMs and conversational AI engineered in India for cognitive automation.
- Architecting custom LLMs and Transformers for complex text analytics.
- Specialists in Sentiment Analysis, NER, and Semantic Search.
- Engineering RAG pipelines for secure, private enterprise AI.
- Delivering multi-lingual NLP and bot solutions from our India hub.
NLP Engineering Excellence for Enterprise Language Solutions









NLP Development Hub in India
Accelerate your linguistic evolution with Webshark’s senior NLP engineers, specialized in building high-performance semantic ecosystems. Our team leverages Transformer architectures, LLM fine-tuning, and specialized tokenization logic to deliver enterprise-grade language solutions that ensure sub-second inference and global scale. By prioritizing vector database orchestration, RAG implementation, and clean-data rigor, we help global leaders reduce technical debt and maintain resilient, production-ready intelligence layers at scale.
Transformer & LLM Design
Engineering custom BERT, GPT, and T5 architectures for high-precision tasks including text generation, summarization, and translation.
Vector Search & RAG
Implementing Retrieval-Augmented Generation (RAG) using Pinecone and Milvus to provide LLMs with private, real-time enterprise data.
Entity & Sentiment Analysis
Utilizing spaCy and Hugging Face for automated data extraction, emotion detection, and high-accuracy Named Entity Recognition (NER).
Intelligent Chatbots
Developing context-aware conversational agents and voice-AI solutions capable of handling complex multi-turn dialogues in various languages.
Tokenization & Cleaning
Building robust pre-processing pipelines for lemmatization, stop-word removal, and byte-pair encoding to ensure clean model inputs.
Graph-Based Intelligence
Integrating NLP models with Knowledge Graphs to provide structured relational insights and improve reasoning capabilities of AI systems.
Core NLP & Language Engineering Specializations
Expert NLP Engineers in India delivering enterprise-grade conversational AI and text analytics.
LLM Fine-Tuning
Adapting Llama and Mistral models using PEFT and LoRA for specific enterprise domain logic.
RAG & Semantic Search
Building RAG pipelines with LangChain and Vector DBs to provide models with private context.
High-Speed NLP APIs
Deploying async FastAPI services for real-time tokenization and dialogue orchestration.
Scalable Vector DBs
Managing high-dimensional embeddings across Milvus or MongoDB for sub-second retrieval.
Knowledge Reasoning
Integrating NLP with Neo4j to build structured knowledge bases for complex relational reasoning.

Microservices Orchestration
Containerizing language models via Docker and gRPC for high-speed inter-service communication.
Featured Work
Production-grade NLP models and language architectures engineered in India for scalable cognitive solutions.
A conceptual redesign enhancing usability, visual clarity, and performance while maintaining the brand’s premium identity.

A conceptual redesign enhancing the digital experience for Stephen Webster’s iconic jewelry collections.

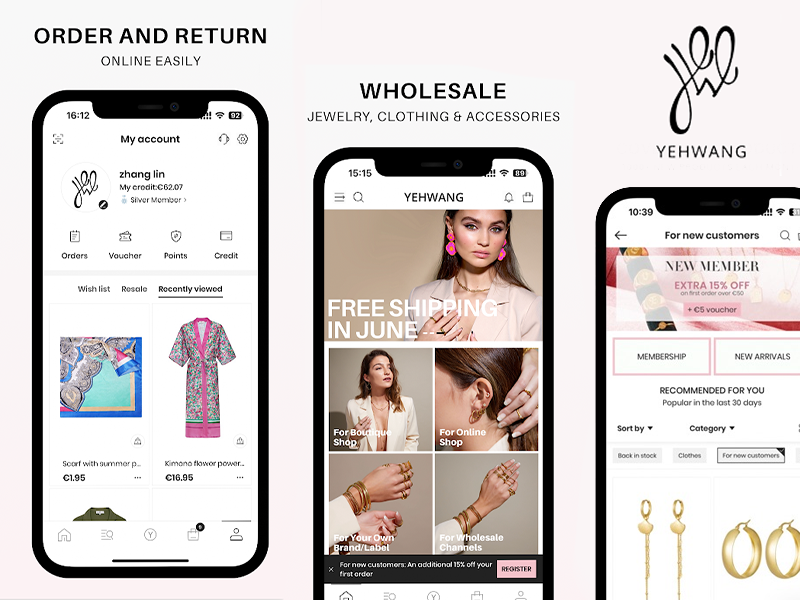
A scalable app redesign focused on faster ordering, improved usability, and a seamless food discovery experience for high-volume, on-demand users.

A high-performance digital redesign blending French elegance with a seamless, personalized e-commerce journey for Gemmyo’s bespoke collections.
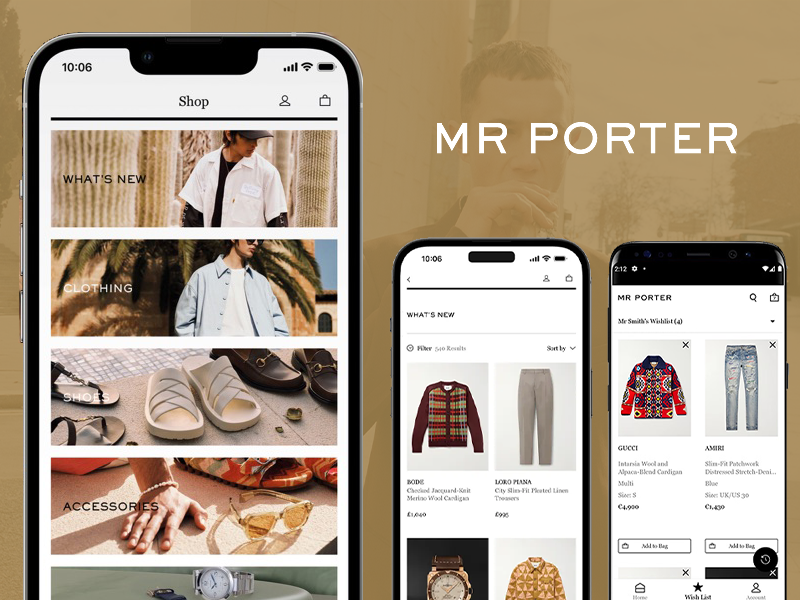
A refined mobile experience designed to showcase products, enhance browsing flow, and elevate brand presence for a fashion-forward global audience.

A sophisticated digital transformation showcasing Haddonstone’s craftsmanship through high-fidelity project visualization and refined product discovery.
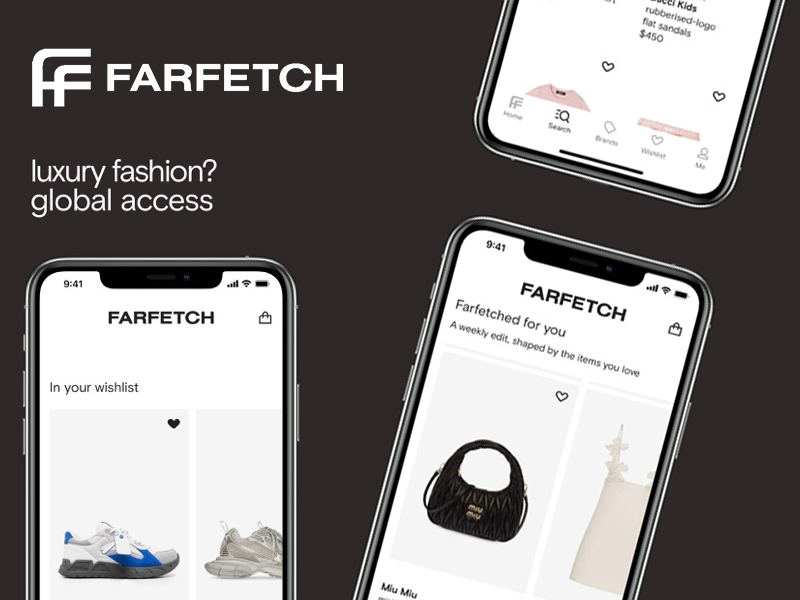
A conceptual redesign focused on premium storytelling, personalized discovery, and seamless navigation across a global luxury fashion marketplace.

A vibrant digital overhaul capturing Free People’s eclectic aesthetic with enhanced visual storytelling and a seamless, community-driven shopping journey.
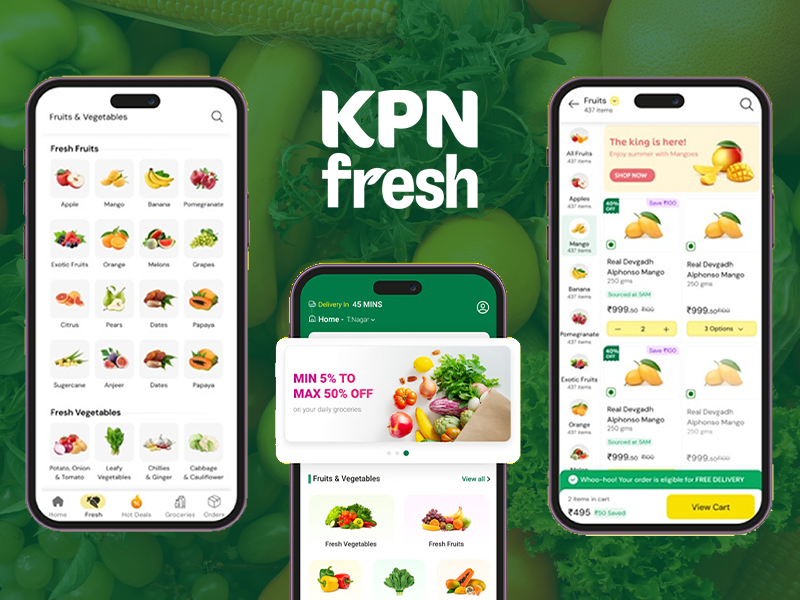
A fast and intuitive grocery delivery app experience focused on easy product discovery, quick reordering, and a seamless checkout journey for everyday shopping.

A sophisticated digital evolution for a Dubai-based construction leader, showcasing five decades of general contracting excellence and landmark regional projects.
Vetting Framework to Hire NLP Specialists
A precision process to integrate elite AI engineers into your natural language processing and LLM ecosystem.
Define Roadmap
Outline tokenization strategies, context window requirements, and domain-specific linguistic benchmarks.
Architectural Vetting
Shortlist experts proficient in Attention mechanisms, Transformer blocks, and BERT/GPT fine-tuning.
Accuracy Validation
Evaluate mastery in RAG optimization, vector embedding logic, and hallucination mitigation techniques.
Production Readiness
Seamless integration into LangGraph, FastAPI, and Docker for scalable, agentic NLP workflows.
Core Development Stack for Production
NLP Engineering & Language Model Systems
NLP Engineering Benchmarks to Mitigate Risk
Proven delivery of enterprise-grade language models designed for high-accuracy semantic reasoning, efficient tokenization, and seamless LLM orchestration across global infrastructures.
Tokens processed across specialized training sets for custom LLM fine-tuning and domain-specific language adaptation in India.
Enterprise NLP projects delivered from our Bangalore hub, ranging from RAG architectures to complex multi-lingual sentiment engines.
Average semantic retrieval latency achieved using optimized Vector Database indexing and high-performance embedding pipelines.
Frequently Asked Questions
Technical insights from our Bangalore engineering hub regarding enterprise NLP development, LLM fine-tuning, and scalable RAG deployment strategies in India.
In our India-based facility, we utilize a multi-layered verification strategy to ensure high groundedness and factual accuracy:
- Citation Verification – Our Bangalore engineers implement cross-referencing logic that forces the LLM to cite specific chunks from your private vector store.
- NLI (Natural Language Inference) – Using entailment models in our Bangalore lab to verify if the generated response is logically supported by the retrieved context.
- Prompt Constraints – Implementing strict system-level instructions within our India hub that prevent the model from answering outside the provided knowledge base.
At our Bangalore facility, the recommendation is typically RAG (Retrieval-Augmented Generation) for 80% of enterprise use cases because it allows for real-time data updates and lower computational costs. However, our India-based NLP specialists pivot to Fine-Tuning (using LoRA or QLoRA) when your project requires the model to adopt a specific tone, jargon, or complex internal reasoning patterns that cannot be achieved via prompting alone. By combining both approaches in our Bangalore lab—a method known as "RAFT"—we ensure your AI in India is both factually current and linguistically specialized.
Selection depends on your existing infrastructure and the scale of embeddings managed from our Bangalore hub:
- Pinecone/Milvus – Utilized for high-scale, cloud-native deployments in India requiring sub-50ms latency for million-scale vector retrieval.
- MongoDB Atlas Vector Search – Our Bangalore team leverages this for clients in India who want to maintain unified operational and vector data in a single cluster.
- ChromaDB/FAISS – Deployed for edge-based or localized NLP applications within our Bangalore facility where data privacy and low overhead are the primary drivers.
Cost efficiency is a priority in our Bangalore lab. Our India-based engineers implement Semantic Chunking and Context Pruning to ensure that only the most relevant data enters the LLM's context window. By utilizing "Small Language Models" (SLMs) like Phi-3 or Mistral-7B for basic summarization tasks and reserving larger models like Llama-3-70B for complex reasoning, our Bangalore hub reduces API overhead by up to 40% without compromising the quality of your India-wide AI deployment.
Yes. Our Bangalore-based NLP specialists are experts in the Bhashini ecosystem and Indic-BERT architectures:
- Cross-Lingual Transfer – Utilizing mBERT and XLM-R in our Bangalore facility to transfer sentiment analysis from English to Hindi, Kannada, and Tamil.
- Tokenization Optimization – Customizing Byte-Pair Encoding (BPE) in our India hub to handle the unique morphologically rich structures of Indian scripts.
- Translation Pipelines – Building high-accuracy NMT (Neural Machine Translation) layers in Bangalore for seamless multi-lingual customer support.
In our Bangalore engineering lab, we combine the probabilistic power of LLMs with the deterministic logic of Knowledge Graphs (GraphRAG). Our India-based specialists use Neo4j to map complex business relationships and entity hierarchies. When a query is made, our Bangalore facility first traverses the graph to extract structured facts, which are then passed to the language model. This hybrid approach—highly sought after in India's finance and healthcare sectors—ensures that the AI doesn't just predict the next word but actually understands the underlying relational logic of your enterprise data.
We move beyond simple metrics like BLEU or ROUGE to specialized "LLM-as-a-judge" frameworks optimized in India:
- RAGAS/DeepEval – Our Bangalore team utilizes these frameworks to measure Faithfulness, Relevancy, and Answer Correctness.
- Human-in-the-Loop – Incorporating subject matter experts from our India hub to validate nuanced technical or legal outputs.
- Latency Benchmarking – Stress-testing inference speeds in our Bangalore facility to ensure real-time responsiveness under heavy traffic.
Data security is the cornerstone of our Bangalore AI lab. In our India-based facility, we implement automated PII (Personally Identifiable Information) Redaction pipelines using Presidio or custom Named Entity Recognition models before any data reaches third-party LLM APIs. For clients in India with extreme privacy requirements, our Bangalore hub specializes in deploying local, air-gapped LLMs using vLLM or Ollama on private cloud infrastructure, ensuring that your sensitive enterprise data never leaves your secure firewall.
We move from static chatbots to agentic workflows using LangGraph and CrewAI in our Bangalore facility:
- Tool Use (Function Calling) – Enabling models to interact with your ERP, CRM, or external APIs directly from our India lab.
- Self-Correction Loops – Architecting agents in Bangalore that can verify their own code or text outputs and re-run tasks if errors are detected.
- Multi-Agent Orchestration – Setting up specialized agent teams in India where one agent researches, another writes, and a third audits the final result.
We maintain a high-velocity talent pipeline in Bangalore to ensure your AI project timeline remains on track. Within 48 to 72 hours, we align a vetted NLP engineer from our India hub with your specific tech stack—be it LlamaIndex, LangChain, or Hugging Face. Full integration into your development sprints and secure repository access usually occurs within 7 to 14 days, allowing our Bangalore team to begin delivering semantic value and architectural improvements to your India-based project immediately.