Hire Machine Learning Engineers In India
Building production AI in India with scalable neural networks and high-accuracy predictive models.
- Experts in LLM Fine-tuning and RAG architectures for Generative AI products.
- Specialists in Computer Vision using PyTorch and OpenCV for real-time analysis.
- Masters of MLOps for seamless deployment and monitoring of automated pipelines.
- Vetted engineers in India delivering data-driven insights through Deep Learning.
Machine Learning Engineering for High-Performance AI Leaders









ML Engineering Hub in India
Accelerate your AI transformation with Webshark’s senior ML engineers, specialized in building high-performance predictive ecosystems. Our team leverages advanced neural architectures, Transformer models, and real-time data orchestration to deliver enterprise-grade AI solutions that ensure sub-second inference and global scale. By prioritizing automated MLOps, rigorous model validation, and CI/CD for ML, we help global leaders reduce technical debt and maintain resilient, production-ready intelligence layers at scale.
LLM & RAG Integration
Architecting custom Large Language Model pipelines with Retrieval-Augmented Generation (RAG) to deliver context-aware, enterprise AI solutions.
Advanced Computer Vision
Developing real-time object detection, facial recognition, and image segmentation models using PyTorch, TensorFlow, and OpenCV.
Predictive Data Modeling
Leveraging statistical learning and deep neural networks to forecast trends, detect anomalies, and optimize business decision-making.
Deep Learning Frameworks
Engineering sophisticated CNN, RNN, and Transformer architectures optimized for high-throughput processing and minimal latency.
Automated MLOps Pipelines
Implementing robust CI/CD for ML, ensuring seamless model versioning, continuous training, and scalable cloud deployment.
Edge AI & Optimization
Quantizing and optimizing complex models for on-device execution (iOS/Android) to ensure privacy and low-latency performance.
Core Machine Learning Technical Specializations
Expert ML engineers in India delivering production-ready AI solutions through specialized mastery of neural architectures and data-driven intelligence.
Generative AI & RAG
Architecting enterprise RAG pipelines and context-aware autonomous agents using GPT-4o and LangChain.
Computer Vision
Engineering real-time object detection and image segmentation models with PyTorch and OpenCV.
Neural Networks
Designing custom CNN and Transformer architectures for high-throughput data processing and low latency.

MLOps & Scaling
Deploying robust CI/CD pipelines using Docker and Kubernetes for seamless model versioning and scale.
Big Data Engineering
Building high-performance ETL pipelines and distributed processing logic using Hadoop and Spark.
Model Optimization
Refining accuracy and performance through Scikit-Learn validation and PyTorch-based inference tuning.
Featured Work
High-accuracy AI models and scalable neural architectures engineered in India for enterprise-level intelligence and automation.
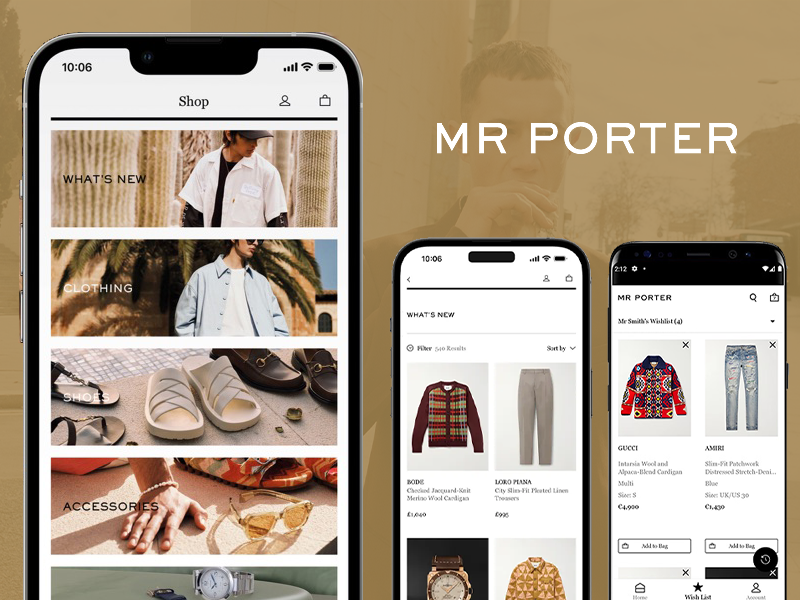
A conceptual redesign enhancing usability, visual clarity, and performance while maintaining the brand’s premium identity.

A conceptual redesign enhancing the digital experience for Stephen Webster’s iconic jewelry collections.

A scalable app redesign focused on faster ordering, improved usability, and a seamless food discovery experience for high-volume, on-demand users.

A high-performance digital redesign blending French elegance with a seamless, personalized e-commerce journey for Gemmyo’s bespoke collections.
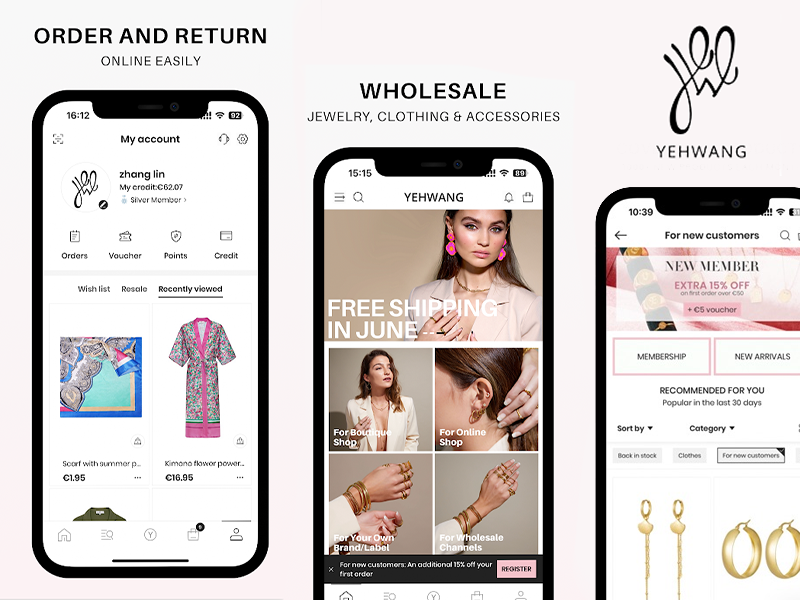
A refined mobile experience designed to showcase products, enhance browsing flow, and elevate brand presence for a fashion-forward global audience.

A sophisticated digital transformation showcasing Haddonstone’s craftsmanship through high-fidelity project visualization and refined product discovery.
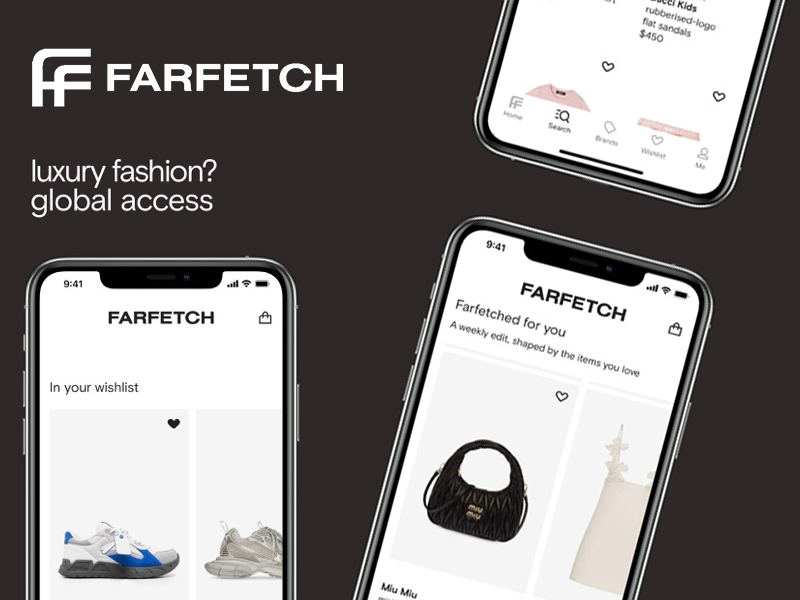
A conceptual redesign focused on premium storytelling, personalized discovery, and seamless navigation across a global luxury fashion marketplace.

A vibrant digital overhaul capturing Free People’s eclectic aesthetic with enhanced visual storytelling and a seamless, community-driven shopping journey.
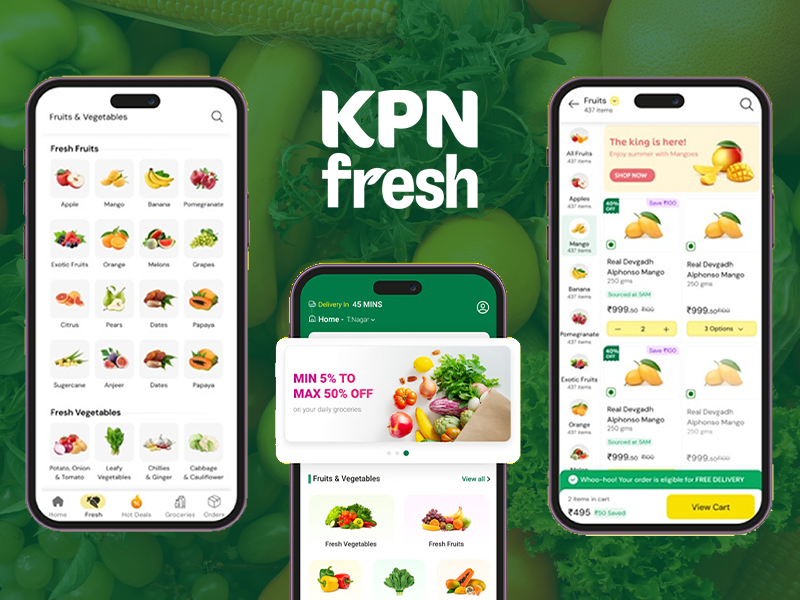
A fast and intuitive grocery delivery app experience focused on easy product discovery, quick reordering, and a seamless checkout journey for everyday shopping.

A sophisticated digital evolution for a Dubai-based construction leader, showcasing five decades of general contracting excellence and landmark regional projects.
Vetting Framework to Hire ML Engineers
A precision process to integrate elite AI specialists into your data infrastructure.
Define AI Roadmap
Outline model requirements, RAG architecture, and cloud or edge deployment targets.
Modeling & Accuracy
Shortlist experts in hyperparameter tuning, transfer learning, and neural architecture validation for precision.
Technical Validation
Evaluate mastery in PyTorch, MLOps, vector databases, and distributed training for enterprise scaling.
Agile MLOps Fit
Seamless onboarding into Docker, Kubernetes, and CI/CD pipelines for AI sprints.
Core Development Stack for Modern
AI & Machine Learning Engineering
ML Benchmarks to Mitigate Risk
Proven delivery of production-grade AI solutions designed for 99% model accuracy and high-throughput automation across enterprise infrastructures.
Years of specialized engineering in Deep Learning, NLP, and Computer Vision from our India hub.
Low-latency inference standards for real-time model predictions and high-velocity data pipelines.
Rapid deployment of vetted ML experts ready to integrate into your MLOps and AI sprints immediately.
Frequently Asked Questions
Technical insights from our Bangalore engineering hub regarding production-grade Machine Learning, RAG architectures, and AI model deployment in India.
Our Bangalore facility adopts PyTorch as the primary framework because its dynamic computational graph allows for faster iteration and more flexible model research compared to static alternatives. This flexibility enables our engineers in India to debug complex neural architectures in real-time, which is critical when building custom Generative AI or Computer Vision solutions that require rapid prototyping. By utilizing PyTorch, we bridge the gap between academic research and production-grade software, ensuring that the latest AI advancements are implemented into your project with high stability and performance.
In our India facility, we maintain high accuracy standards by implementing a rigorous validation-first pipeline:
- K-Fold Cross-Validation – Ensuring model stability across diverse and unseen datasets.
- Bias Mitigation Audits – Identifying and eliminating algorithmic bias in training data.
- Bayesian Optimization – Fine-tuning hyperparameters for peak model efficiency.
Absolutely. We specialize in Retrieval-Augmented Generation (RAG) to provide context-aware AI that utilizes your private enterprise data securely without the need for constant model retraining. By integrating vector databases with LLMs like GPT-4, our India-based specialists create autonomous agents that significantly reduce hallucinations and provide verified, source-backed responses for customer support or internal knowledge management. This architecture ensures that your AI stays current with your latest business data while maintaining a strict boundary between public models and your proprietary information.
Webshark’s Bangalore hub ensures data privacy through these specific ML-focused protocols:
- VPC Deployment – Keeping models within your private cloud to prevent data leakage.
- PII Scrubbing – Anonymizing sensitive user information before training begins.
- Secure Inference – Utilizing encrypted SSL/TLS channels for all model communications.
Our developers in Bangalore follow an automated MLOps philosophy that treats model deployment with the same rigor as traditional software engineering. We utilize Docker for consistent containerization and Kubernetes for orchestration to ensure that your models can scale horizontally across different cloud regions or on-premise clusters. By implementing robust CI/CD pipelines specifically for Machine Learning, our India team ensures that new model versions are automatically tested, validated against performance benchmarks, and deployed without any downtime, maintaining 2026 performance standards for global user bases.
Yes. We optimize complex models for on-device execution through specialized techniques:
- Quantization – Reducing model size to run on mobile hardware without losing precision.
- Core ML & TensorFlow Lite – Seamlessly integrating AI into iOS and Android apps.
- NPU Optimization – Leveraging hardware accelerators for low-latency local inference.
Our Bangalore specialists utilize advanced distributed computing tools like Apache Spark and Hadoop to engineer high-throughput ETL pipelines that can handle massive datasets. We focus on transforming terabytes of raw, unstructured data into clean, feature-rich datasets that are optimized for model training and real-time inference. By ensuring your data lake is properly partitioned and optimized for fast access, we significantly reduce the time and computational costs associated with large-scale AI projects, making sophisticated data science more accessible for businesses operating in the Indian and global markets.
We implement continuous monitoring to ensure long-term model reliability through:
- Performance Tracking – Real-time monitoring of inference accuracy and latency.
- Drift Detection – Identifying when live data diverges from training distributions.
- Auto-Retraining – Triggering fresh training cycles to keep models current with shifting trends.
Our team in India specializes in re-architecting and migrating legacy models to modern cloud platforms like AWS SageMaker, Google Vertex AI, or Azure ML. We manage the entire lifecycle of the migration, from setting up Infrastructure as Code (IaC) to ensure reproducible environments to optimizing API endpoints for low-latency global access. This transition is handled with a focus on cost-efficiency and scalability, ensuring that your migrated AI infrastructure can handle the increased demand of 2026 and beyond without requiring constant manual intervention or over-provisioning of expensive GPU resources.
We maintain a streamlined talent pipeline in India to ensure your project maintains momentum:
- 48 Hours – Identifying a vetted ML engineer with expertise in your domain.
- 3-5 Days – Secure environment setup and access to your data workflows.
- 7-14 Days – Full integration into your Agile ceremonies and active AI sprints.